See architectural details here, gaddie pitch and business plan
Hybrid 3D GPU / CPU / VPU
Creating a trustworthy processor for the world.
Note: this is a hybrid CPU, VPU and GPU. It is not, as many news articles are implying, a "dedicated exclusive GPU". The option exists to create a stand-alone GPU product (contact us if this is a product that you want). Our primary goal is to design a complete all-in-one processor (System-on-a-Chip) that happens to include libre-licensed VPU and GPU accelerated instructions as part of the actual - main - CPU itself. This greatly simplifies driver development, applications integration and debugging, reducing costs and time to market in the process.
We seek investors, sponsors (whose contributions thanks to NLNet may be tax-deductible), engineers and potential customers, who are interested, as a first product, in the creation and use of an entirely libre low-power mobile class system-on-a-chip m class. Comparative benchmark performance, pincount and price is the Allwinner A64, except that the power budget target is 2.5 watts in a 16x16mm 320 to 360 pin 0.8mm FBGA package. Instead of single-issue higher clock rate, the design is multi-issue, aiming for around 800mhz.
The lower pincount, lower power, and higher BGA pitch is all to reduce the cost of product development when it comes to PCB design and layout:
- Above 4 watts requires metal packages, greater attention to thermal management in the PCB design and layout, and much pricier PMICs.
- 0.6mm pitch BGA and below requires much more expensive PCB manufacturing equipment and more costly PCBA techniques.
- Above 600 pins begins to reduce production yields as well as increase the cost of testing and packaging.
We can look at larger higher-power ASICs either later or, if funding is made available, immediately.
Recent applications to NLNet (Oct 2019) are for a test chip in 180nm, 64 bit, single core dual issue, around 300 to 350mhz. This will provide the confidence to go to higher geometries, as well as be a commercially viable embedded product in its own right. Tapeout deadline is Oct 2020.
See articles online.
Progress:
- Dec 2021 first MMU unit tests pass, running microwatt mmu.bin. Shows MMU and L1 D/I-Caches as functional in simulation.
- Apr 2021 cocotb simulation of 180nm ASIC implemented. JTAG TAP confirmed functional on ECP5 and simulation. FreePDK-c4m45 created by https://chips4makers.io
- Mar 2021 first SVP64 OpenPOWER augmented Cray-style instructions executed. NGI POINTER EUR 200,000 grant submitted.
- Feb 2021 FOSDEM2021, Simple-V SVP64 implementation starts in simulator and Test Issuer
- Jan 2021 FOSDEM2021 talks confirmed, NLnet crypto-primitives proposal submitted, budget agreed for basic binutils and gcc SVP64 support
- Dec 2020 work on svp64 started
- Nov 2020 dry-run 180nm GDSII sent to IMEC
- Oct 2020 ls180 pinouts decided, code-freeze initiated for 180nm test ASIC, GDSII deadline set of Dec 2nd.
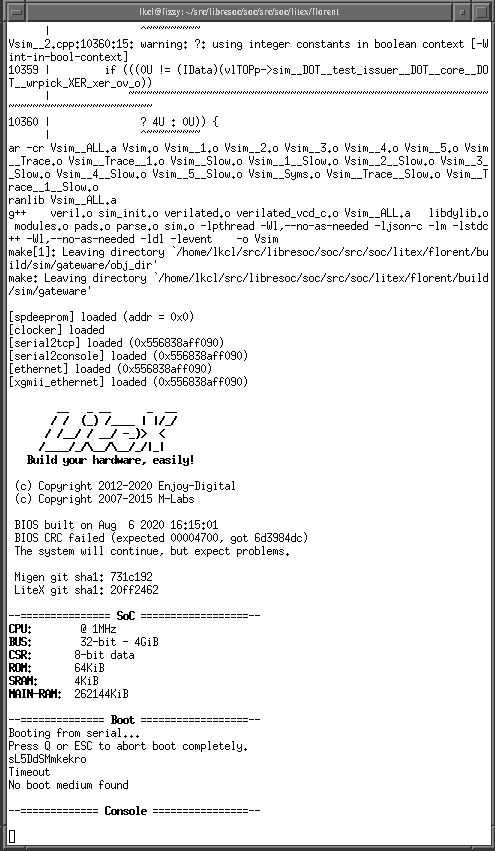
- Sep 2020: first boot of Litex BIOS on a Versa ECP5 at 55mhz. DDR3 RAM initialisation successful. 180nm ASIC pinouts started ls180
- Aug 2020: first boot of litex BIOS in verilator simulation
- Jul 2020: first ppc64le "hello world" binary executed. 80,000 gate coriolis2 auto-layout completed with 99.98% routing. Wishbone MoU signed making available access to an additional EUR 50,000 donations from NLNet. XDC2020 and OpenPOWER conference submissions entered.
- Jun 2020: core unit tests and pipeline formal correctness proofs in place.
- May 2020: first integer pipelines (ALU, Logical, Branch, Trap, SPR, ShiftRot, Mul, Div) and register files (XER, CR, INT, FAST, SPR) started.
- Mar 2020: Coriolis2 Layout experiments successful. 6600 Memory Architecture exploration started. OpenPOWER ISA decoder started. Two new people: Alain and Jock.
- Feb 2020: OpenPower Foundation EULA released. Coriolis2 Layout experimentation begun. Dynamic Partitioned SIMD ALU created.
- Jan 2020: New team members, Yehowshua and Michael. Last-minute attendance of FOSDEM2020
- Dec 2019: Second round NLNet questions answered. External Review completed. 6 NLNet proposals accepted (EUR 200,000+)
- Nov 2019: Alternative FP library to Berkeley softfloat developed. NLNet first round questions answered.
- Oct 2019: 3D Standards continued. POWER ISA considered. Open 3D Alliance begins. NLNet funding applications submitted.
- Sep 2019: 3D Standards continued. Additional NLNet Funding proposals discussed.
- Aug 2019: Development of "Transcendentals" (SIN/COS/ATAN2) Specifications
- Jul 2019: Sponsorship from Purism received. IEEE754 FP Mul, Add, DIV, FCLASS and FCVT pipelines completed.
- Jun 2019: IEEE754 FP Mul, Add, and FSM "DIV" completed.
- May 2019: 6600-style scoreboard started
- Apr 2019: NLnet funding approved by independent review committee
- Mar 2019: NLnet funding application first and second phase passed
- Mar 2019: First successful nmigen pipeline milestone achieved with IEEE754 FADD
- Feb 2019: Conversion of John Dawson's IEEE754 FPU to nmigen started
- Jan 2019: Second version Simple-V preliminary proposal (suited to LLVM)
- 2017 - Nov 2018: Simple-V specification preliminary draft completed
- Aug 2018 - Nov 2018: spike-sv implementation of draft spec completed
- Aug 2018: Kazan Vulkan Driver initiated
- Sep 2018: mailing list established
- Sep 2018: Crowdsupply pre-launch page up (for updates)
- Dec 2018: preliminary floorplan and architecture designed (comp.arch)
{kind=link}